
15. HPC resource manager: Slurm#
Slurm, https://slurm.schedmd.com/documentation.html, is a resource manager and job scheduler that allows to organize and share resources in a HPC environment to get an optimal usage. It allows to specify usage policies, limits in terms of memory or cpu etc, to get metrics regarding the cluster usage, and so on. You can watch a good intro at https://www.youtube.com/watch?v=NH_Fb7X6Db0 and related videos.
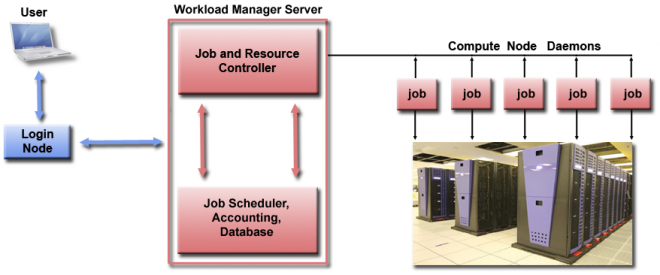
In particular, slurm follows the following arquitechture
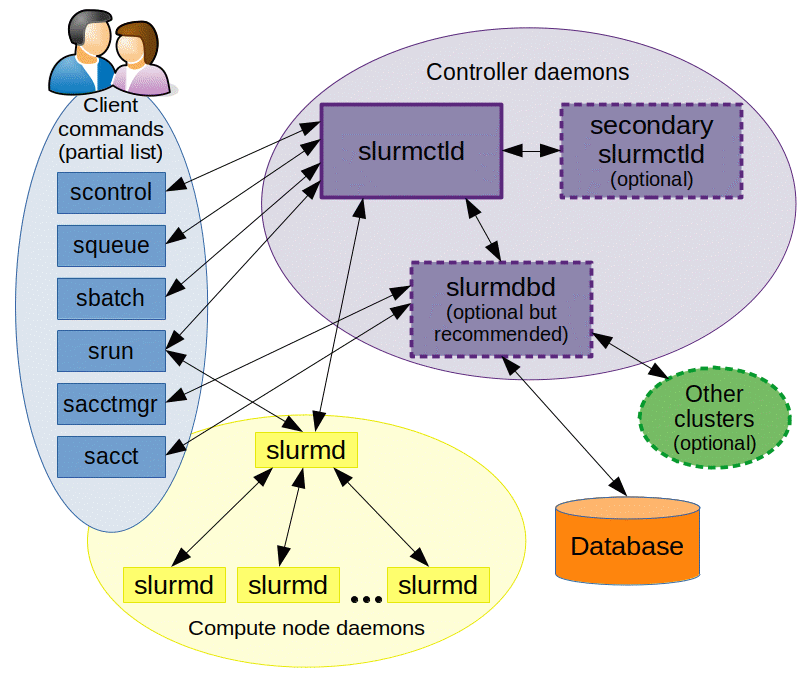
Slurm common workflows:
Single-core jobs
Multi-core (OpenMP): Needs cpu per task specification
Multi-node (MPI): Need nodes specification
Array jobs for parameter sweeps
Here we will use a very simple installation in the computer room. Our goal will be to learn some of the basic commands to get the possible resources, how to specify a partition, limits, resources and so on.
In general, you should run all cluster jobs through slurm, not run them directly on each node.
For the computer room: you need to connect to the public server ip
First of all, log into a client and use the command sinfo to get
information about partitions:
sinfo --all
PARTITION |
AVAIL |
TIMELIMIT |
NODES |
STATE |
NODELIST |
|---|---|---|---|---|---|
4threads |
up |
infinite |
5 |
idle |
sala[16-20] |
6threads |
up |
infinite |
3 |
idle |
sala[13-15] |
8threads |
up |
infinite |
3 |
idle |
sala[11-12,21] |
12threads* |
up |
infinite |
8 |
idle |
sala[7-10,26-29] |
16threads |
up |
infinite |
9 |
idle |
sala[2-6,22-25] |
GPU |
up |
infinite |
1 |
idle |
sala2 |
As you can see in this example, there are several partitions available
to be used. The 12threads partition is the default. Some nodes
might not working and will be shown as down. There is not time limit besides the login
node (which actually should not be used for any job). Use the manual and
get some other info about the resources.
A more powerful cluster can be seen here:
To see the state of your running processes, use
squeue
If you want something more elaborated, you can check slurmer: wjwei-handsome/Slurmer
Now let’s run some simple commands in the cluster. To do so, we will use
the simple command srun (check the manual)
srun hostname
As you can see here, the command actually ran in the 12threads
partition since we did not specify the actual partitions and 12threads
is the default.
Run 18 instances of the same command in a non-default
partition. You should get something like (12threads partition). Use the parameter -N.
SERVER |
|---|
sala7.salafis.net |
sala7.salafis.net |
sala7.salafis.net |
sala7.salafis.net |
sala7.salafis.net |
sala7.salafis.net |
sala7.salafis.net |
sala7.salafis.net |
sala7.salafis.net |
sala7.salafis.net |
sala8.salafis.net |
sala8.salafis.net |
sala8.salafis.net |
sala8.salafis.net |
sala8.salafis.net |
sala8.salafis.net |
sala8.salafis.net |
sala8.salafis.net |
As you can see, the jobs where magically distributed among two nodes
necessary to run 18 processes (each node allows for 12 processes, two
nodes corresponds to 24 processes in total). If you want to see this
better, use the stress command with a timeout of 10 seconds and check
that as soon as you launch the process, two nodes will be using their
cpus at full (have some htop command running on both nodes):
srun -p 12threads -n 18 stress -t 10 -c 1
You can also cancel a slurm process using scancel. For a quick slurm command overview, check https://www.carc.usc.edu/user-guides/hpc-systems/using-our-hpc-systems/slurm-cheatsheet and https://docs.unity.uri.edu/documentation/jobs/slurm/
15.1. Creating slurm scripts for batch processing#
In general, it is advisable to put your slurm commands in a bash script to be able to improve them, have a historical track and so on. You can employ a special syntax in your script to give all
the info to slurm and then use the command sbatch to launch your
script , and squeue to check its state.
For our example, we will need to generate and adapt to finally get something like
#!/bin/bash -l
#SBATCH --job-name="testmulti"
# #SBATCH --account="HerrComp" # not used
#SBATCH --mail-type=ALL
#SBATCH --mail-user=wfoquendop@unal.edu.co
#SBATCH --time=01:00:00
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=12
#SBATCH --cpus-per-task=1
#SBATCH --partition=12threads
export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK
srun hostname
and then run it as
sbatch run.sh
You can get info about the jobs (if it is running, pending, cancelled,
etc) using the command squeue .
By default you will get the standar output and error written in some *.out and *.err files, respectively.
Slurm.org |
run.sh |
slurm-70.out |
Using a slurm script allows for a very general way to both run commands
and specifiy , for instance, what modules to load, like using
ml somehpclib or spack load something.
There are many env vars that you can access with slurm: check https://slurm.schedmd.com/sbatch.html and https://docs.hpc.shef.ac.uk/en/latest/referenceinfo/scheduler/SLURM/SLURM-environment-variables.html#gsc.tab=0
You can use a script generator to make this task easier:
Adapt and run the following script to show some env vars automatically set by slurm
...
echo "Job ID: $SLURM_JOB_ID"
echo "Node: $(hostname)"
echo "CPUs: $SLURM_CPUS_ON_NODE"
echo "Dir: $SLURM_SUBMIT_DIR"
15.2. Exercises#
Create a script to run the stress command in some partition, including several nodes. Log into those nodes and check the actual usage. Share with other students.
Create a slurm script to run the openmp vector average, also including the scalling study. Check if sharing the nodes affects or not the times measured.
Create a slurm script to run the eigen matrix matmul example with openmp. Also use another one for the scaling study.
Create a slurm script to run some program that needs
spack
15.3. Job array#
A job array allows slurm to run many commands parametrically.
Write a script that prints the value of a parameter using $SLURM_ARRAY_TASK_ID
Submit with –array=1-5
Run a job array job to compute the time metrics for eigen c++ solving a linear algebra problem. Notice that now you dont need to worry about using only the available number of cpus.